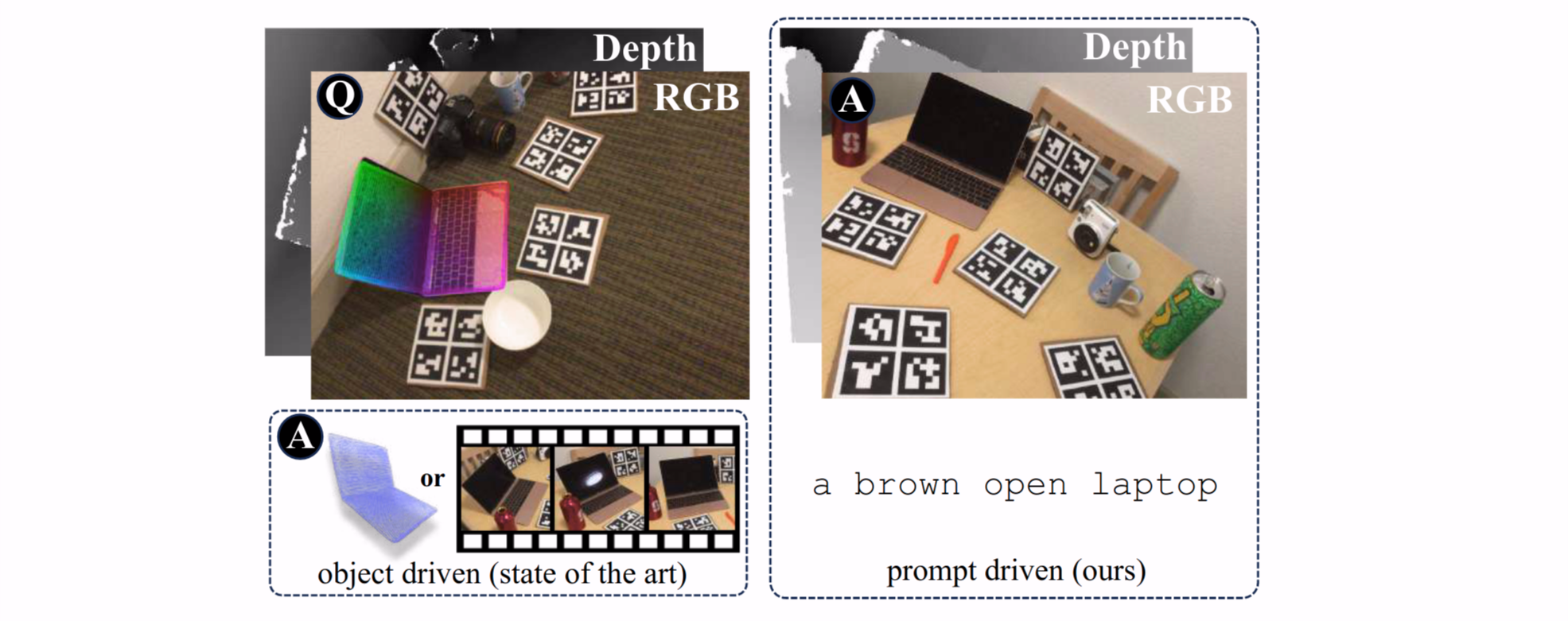
We introduce the new setting of open-vocabulary object 6D pose estimation, in which a textual prompt is used to specify the object of interest. In contrast to existing approaches, in our setting (i) the object of interest is specified solely through the textual prompt, (ii) no object model (e.g.,~CAD or video sequence) is required at inference, and (iii) the object is imaged from two RGBD viewpoints of different scenes. To operate in this setting, we introduce a novel approach that leverages a Vision-Language Model to segment the object of interest from the scenes and to estimate its relative 6D pose. The key of our approach is a carefully devised strategy to fuse object-level information provided by the prompt with local image features, resulting in a feature space that can generalize to novel concepts. We validate our approach on a new benchmark based on two popular datasets, REAL275 and Toyota-Light, which collectively encompass 34 object instances appearing in four thousand image pairs. The results demonstrate that our approach outperforms both a well-established hand-crafted method and a recent deep learning-based baseline in estimating the relative 6D pose of objects in different scenes.
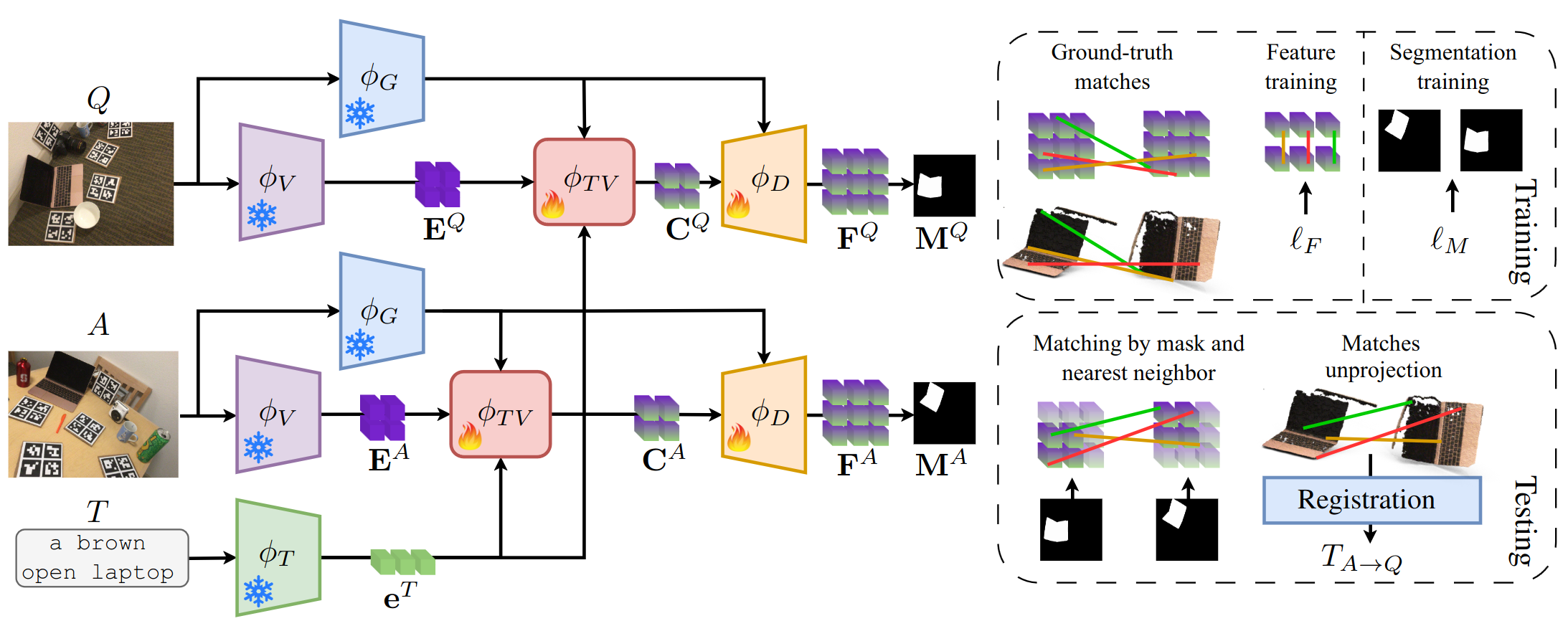
We address relative pose estimation by finding the matches between the anchor scene \(A\) and the query scene \(Q\), and subsequently lifting the matches to 3D and perform registration to retrieve the final poses. The textual prompt \(T\) is used to locate the object of interest in the scene pair and to guide the feature extraction process. The two scenes are encoded with the CLIP image encoder \(\phi_{V}\), obtaining a pair of feature maps \(\mathbf{E}^A\), \(\mathbf{E}^Q\), while \(T\) is processed by the CLIP text encoder \(\phi_T\), obtaining the textual features \(\mathbf{e}^T\).
In order to relate the textual and visual features, we adopt a fusion module \(\phi_{TV}\) based on cost-aggregation, which also leverages the features from a guidance backbone \(\phi_G\). A decoder architecture \(\phi_D\) is used to increase the resolution of the feature maps, thus obtaining a pair of feature map \(\mathbf{F}^A\), \(\mathbf{F}^Q\), suitable for fine-grained matching. The same feature maps are processed by a segmentation head to obtain the predicted masks \(\mathbf{M}^A\), \(\mathbf{M}^Q\).
At training time, the feature maps are optimized by an hardest contrastive loss \(\ell_F\), while the segmentation masks are trained supervisedly by \(\ell_M\). At test time, matches between \(\mathbf{F}^A\) and \(\mathbf{F}^Q\) are computed by nearest neighbor, and the masks \(\mathbf{M}^A\), \(\mathbf{M}^Q\) are used to filter the matches in order to retain only the ones on the object of interest. The resulting matches converted to 3D and a point cloud registration algorithm is used ot obtain the final pose \(T_{A \rightarrow Q}.\)

Oryon is evaluated on a challenging scenario in which \(A\) and \(Q\) show different scenes. We compare Oryon with the results from a well-established hand-crafted baseline (SIFT) and a state-of-the art method specialized in point cloud registration with low overlap (ObjectMatch). Our method shows accurate pose estimation performance even with small objects.

We show examples of how the feature map is influenced by the textual prompt \(T\), by visualizing the distance in the feature space with respect to a reference point on the anchor image (in green). The choice of the prompt greatly influences the composition of the feature map and the performance.
@inproceedings{corsetti2024oryon,
title= {Open-vocabulary object 6D pose estimation},
author = {Corsetti, Jaime and Boscaini, Davide and Oh, Changjae and Cavallaro, Andrea and Poiesi, Fabio},
journal = {IEEE/CVF Computer Vision and Pattern Recognition Conference (CVPR)},
year = {2024}
}